提示工程
1. 两大原则
原则 1:编写清晰具体的说明
使用分隔符
- 三引号:”””
- 三个反引号:```
- 三个破折号:—
- 尖括号:<>
- XML标签:
要求结构化输出
- HTML
- JSON
- XML
- Python字典
检查条件是否满足
- 检查执行任务所需的假设
少量样本提示
- 先给出完成任务的成功示例
- 如何再让模型执行任务
原则2:给模型足够的时间思考
指定任务完成的步骤:
第一步:…….第二步:…….
第三步:…….
…
第N步:…….
指示模型在给出结论之前提出自己的解决步骤(方案)
提醒
要注意LLM的“幻觉”(hallucination)现象,就是LLM会一本正经的胡说八道,给出一些错误信息,往往这些错误信息难以发觉。
避免手段:要求LLM首先找到相关引用,然后要求它使用这些引用来回答问题
2. 迭代
一般来说我们很难一次性就让LLM输出我们想要的内容,我们可以根据当前输出的内容以此基础一步一步迭代出我们想要的内容,大概过程如下
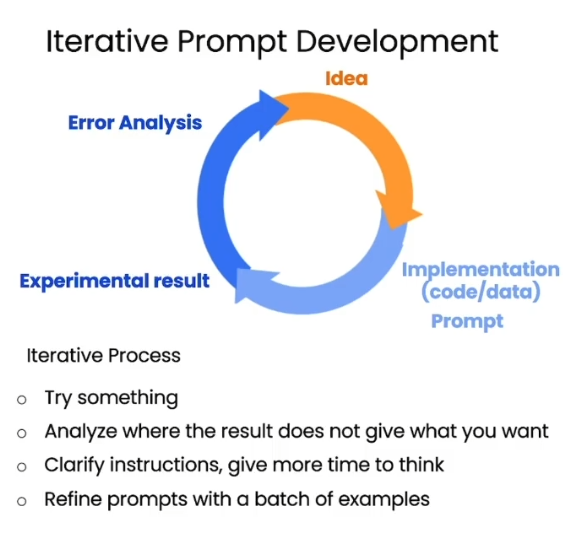
其中,第四步指的是在一些实践中,我们可以用小批量的测试来改进我们的prompts
3. 摘要
我们可以很方便的利用LLM来进行一些文字总结、提炼的工作
- 生成文章摘要
- 总结,可以带入上下文,让LLM进行更有针对性的总结,例如顾客对某件商品的评价,如果我们是商家,我们可以让LLM更侧重于总结价格之类的情况,而如果我们是快递公司,我们可以让LLM更侧重于总结快递速度之类的情况
4. 推理
情感分析,可以利用LLM进行结构化输出,例如对某件商品的评论区,可以逐条评论进行情感分析来了解多少个好评多少个差评,例如:
f'''这是一个商品的评价,请你分析一下这是一条好评还是差评,如果是好评,就输出True,否则输出False,评价如下{msg}'''
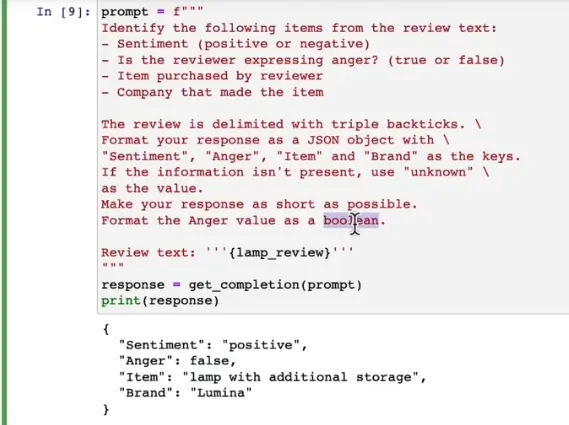
可以将自己想知道的信息封装为一个json来利用大模型进行结构化输出,例如
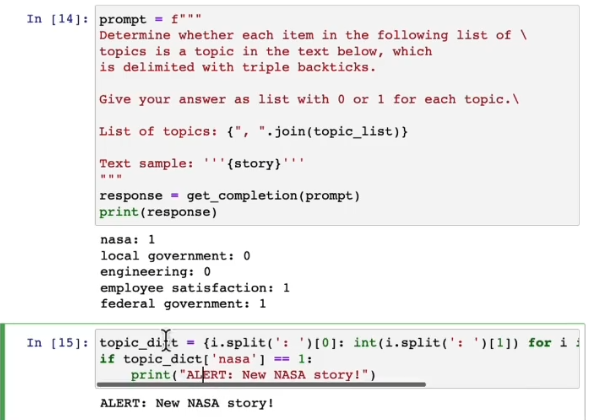
关键词总结,下面是一个关键词总结的应用,旨在读取某一段新闻,如果该新闻是关于nasa的,就告警(这个代码不太健壮,因为每种大模型输出可能不太相同,我们可以让它输出JSON格式来增强代码的健壮性)
5. 转换
最多应用的就是翻译,在进行翻译时候我们需要注意到不同语言在不同场合和心情下翻译出来是不一样的,因此我们可以加上我们要翻译的句子的语境
当你输入一段文字,让大模型说出是什么语言时,可以让它就用一个词来回答,从而获得结构化数据
可以将不太正式的语言转换为正式语言,例如JSON,XML,字典相互转换
拼写检查和语法检查,对外语尤其有用可以使用一些工具来展示错误


6. 扩展
- 是指将短文本(例如一组说明或者主题列表)通过大语言模型转化为更长的文本(如一封电子邮件或一篇关于某个主题的文章)
- 例如我们可以根据客户在产品评论区对于产品的评价进行个性化回复
- temperature,指模型的随机性,值越小,模型越稳定,值越大,模型创造力更强,输出更不稳定
7. 聊天机器人
疑点解决:要达到聊天效果,也就是让LLM记住上下文,需要在本地存储上下文,每次发送给LLM时需要在前面加上上下文